


神經網路的黑盒子特色
神經網路依照過往資料訓練,在高度複雜的問題裡,藉由複雜的結構從中訓練出能讓訓練資料錯誤率自主逐步降低的一個經典演算法。
因為複雜結構的關係,目前僅知道神經網路有強擬合的特性,但如何從中分析擬合過程與辦法,我們無從得知,所以許多學者稱它為黑盒子。

驗證神經網路在隨機問題裡的可行性
我們真正要確認的是,
神經網路是否能在高度的隨機裡找到隱含的規則。
以此為發想,我們可以設計一套模型。
設定簡單規則,其餘的內容都隨機,製造大量數據,讓神經網路訓練。
查看其訓練成果能否查找出我們設計的規則。
股市裡的隨機漫步
股票市場亦是如此,古今中外有許多學者與投資者在股票市場的殿堂外,藉由有限的資訊以管窺天試圖臨摹股票市場內是否真有一條優美的式子整合著整個市場的脈絡,抑或市場真的僅是瘋狂的人心混亂隨機漫步。
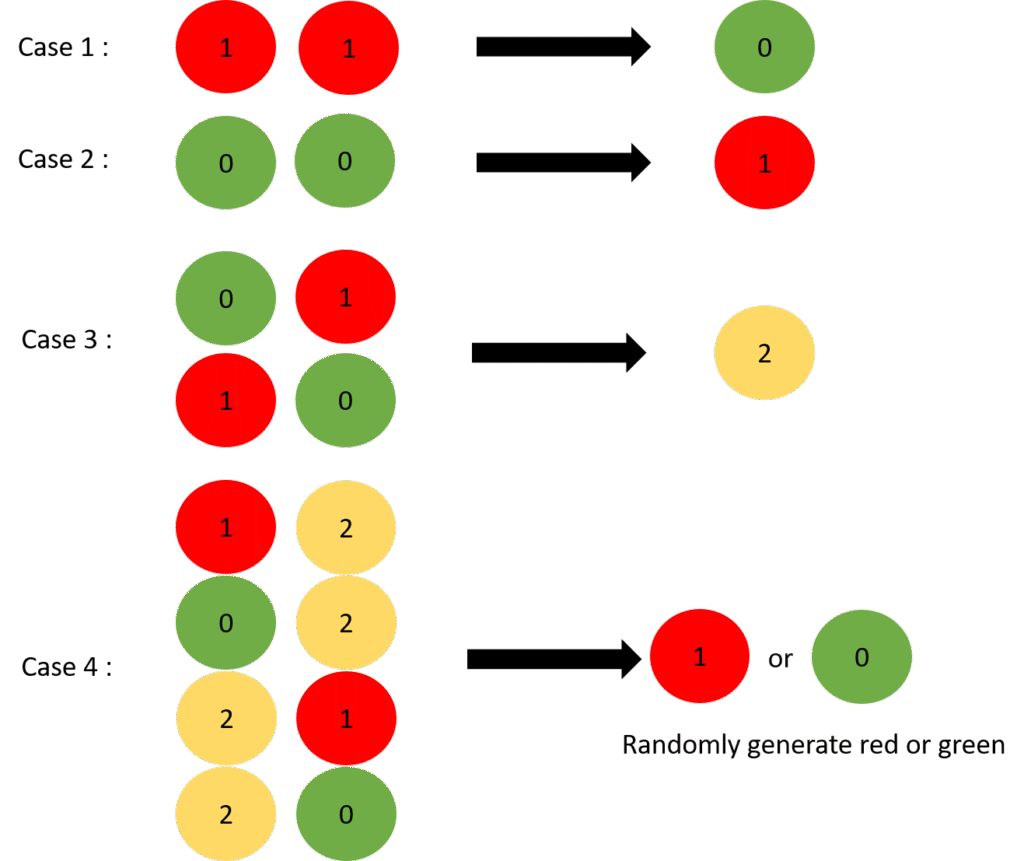

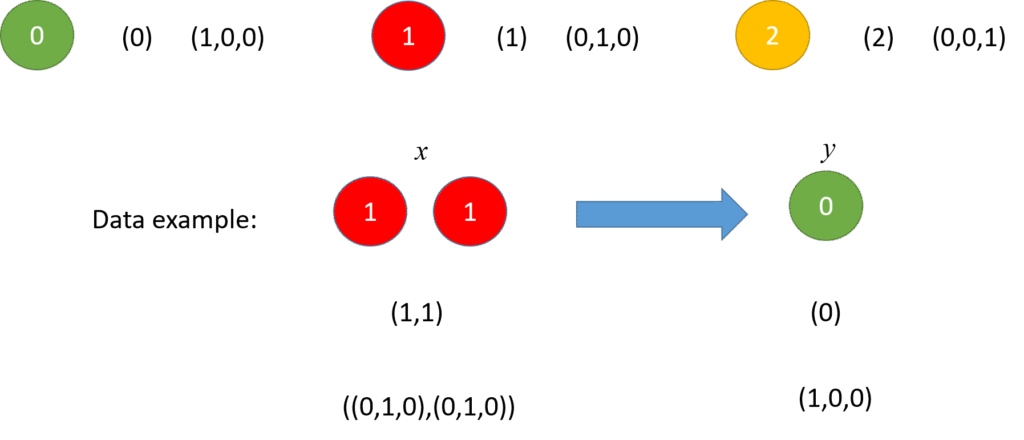
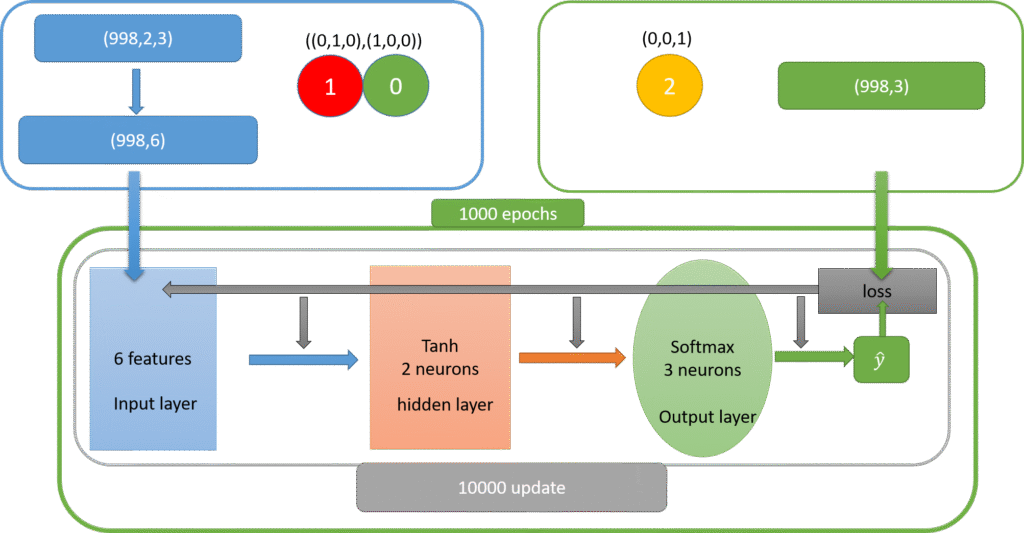


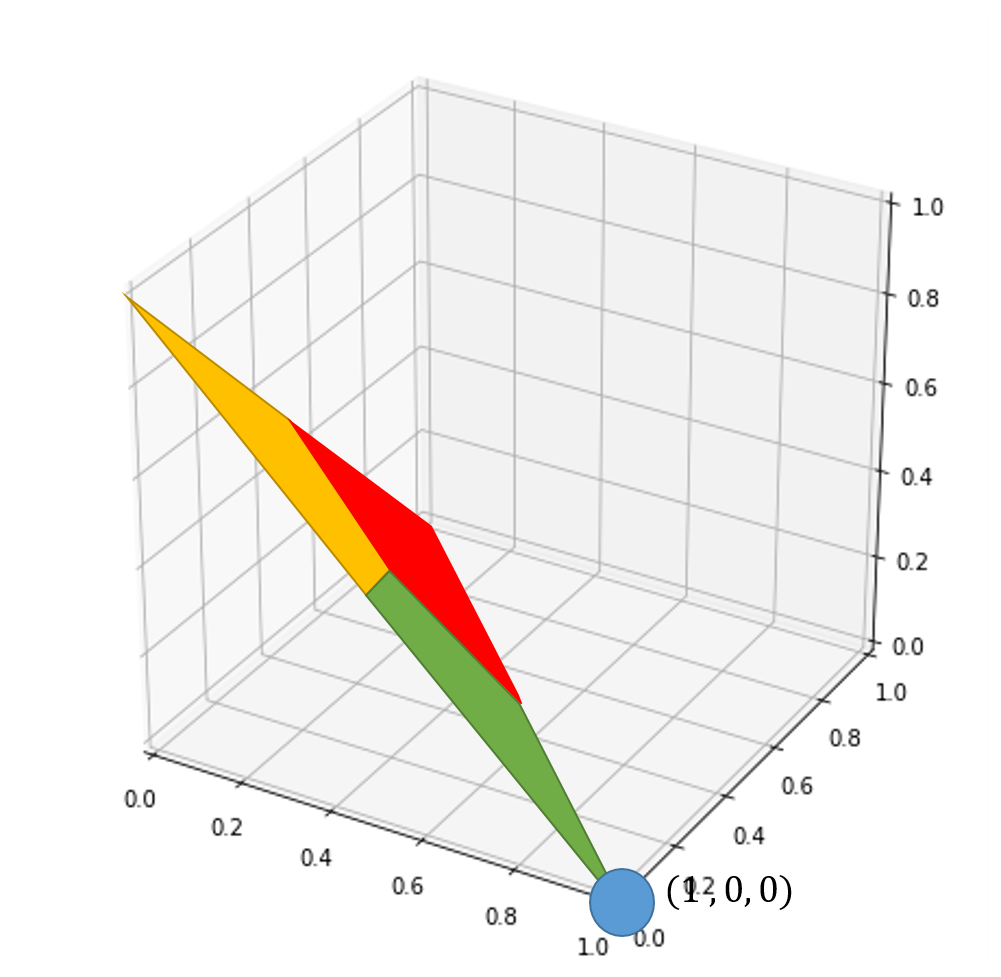
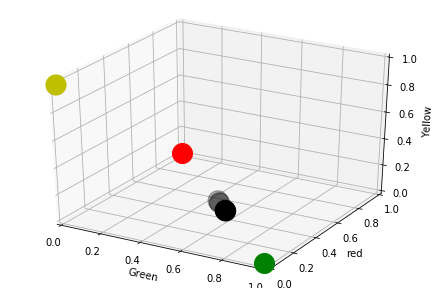
當輸入值是兩個紅球時
我們希望輸出結果必須判斷出綠球
同時需要接近100%的信心程度
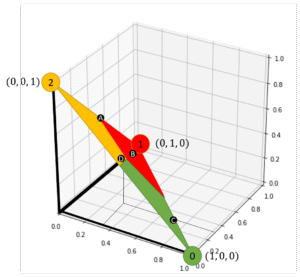
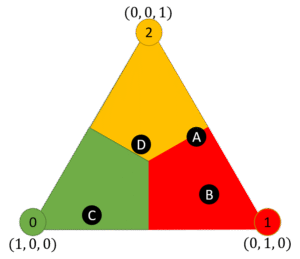
可視化上需要再座標(1,0,0)附近
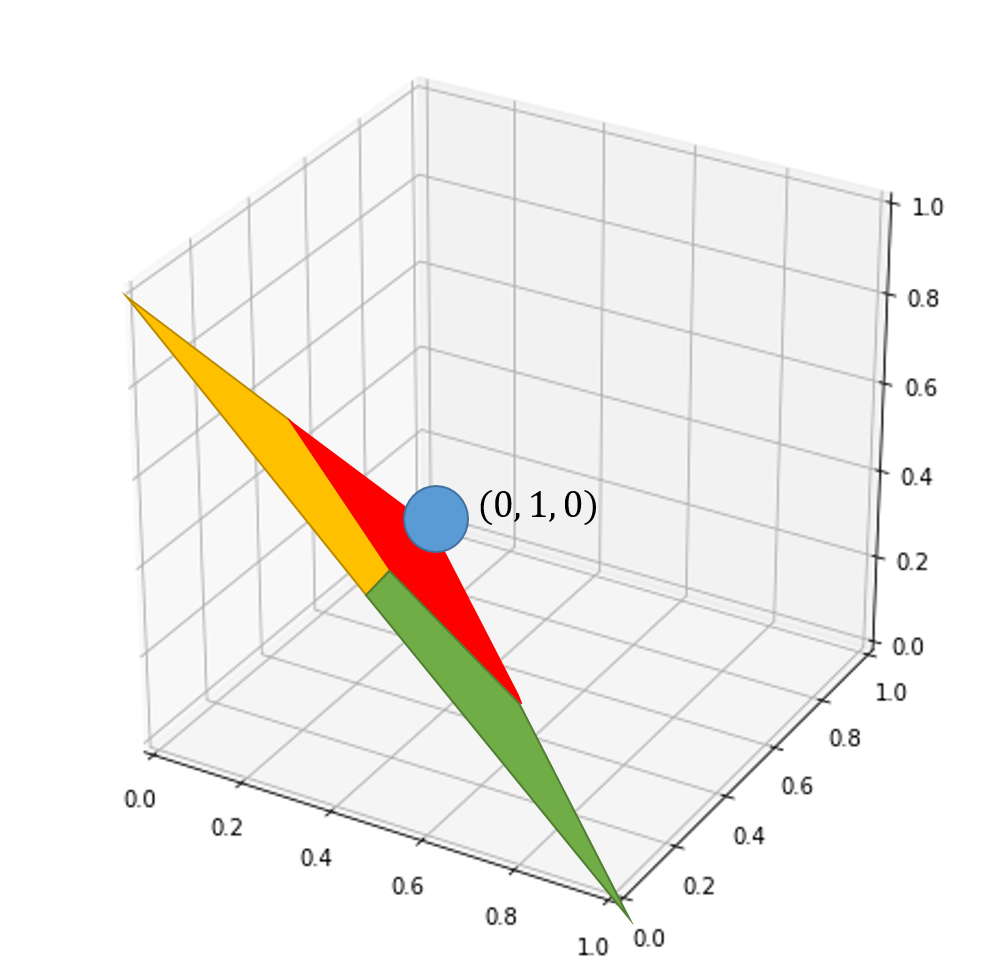
當輸入值是兩個綠球時
我們希望輸出結果必須判斷出紅球
同時需要接近100%的信心程度
可視化上需要再座標(0,1,0)附近

當輸入值x是紅綠或綠紅相間
我們希望輸出結果必須判斷出黃球
同時需要接近100%的信心程度
可視化上需要再座標(0,0,1)附近
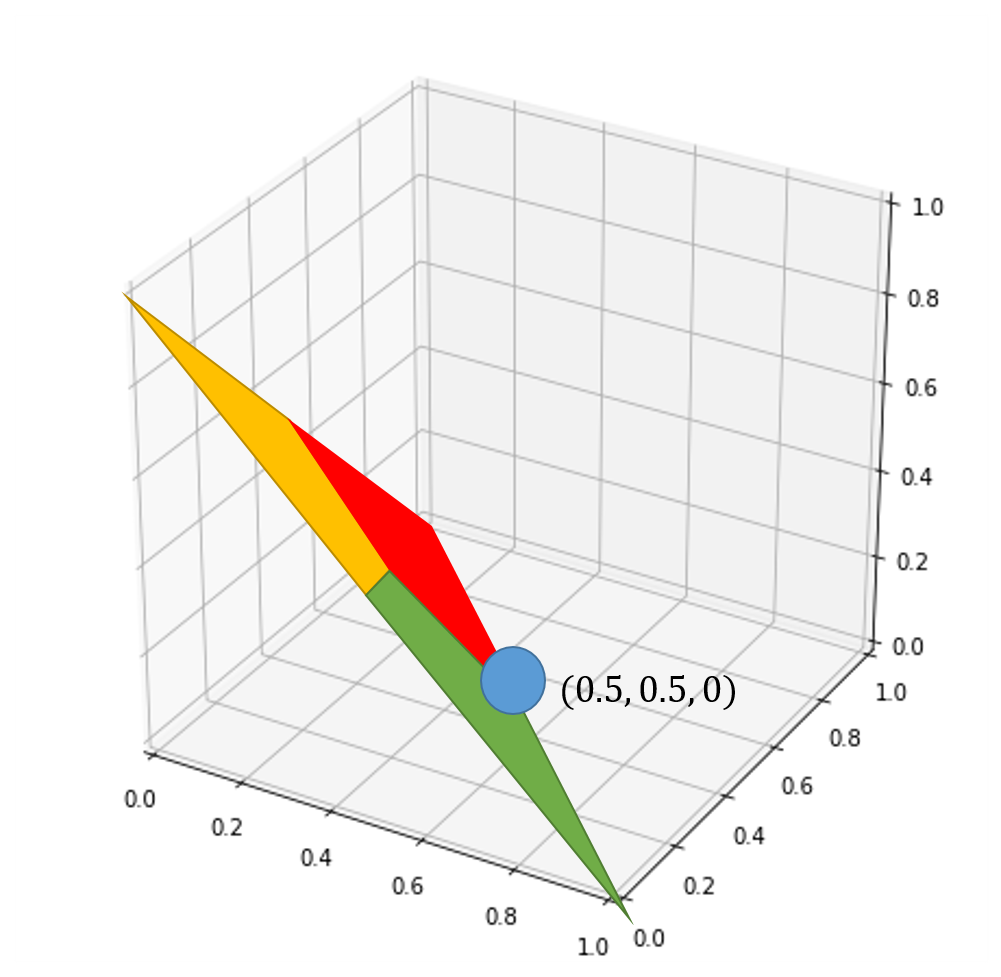
當輸入值是其他情況時
輸出值,只能答出紅跟綠。
同時紅跟綠信心程度必須50%左右,
黃球的信心程度需要接近0%
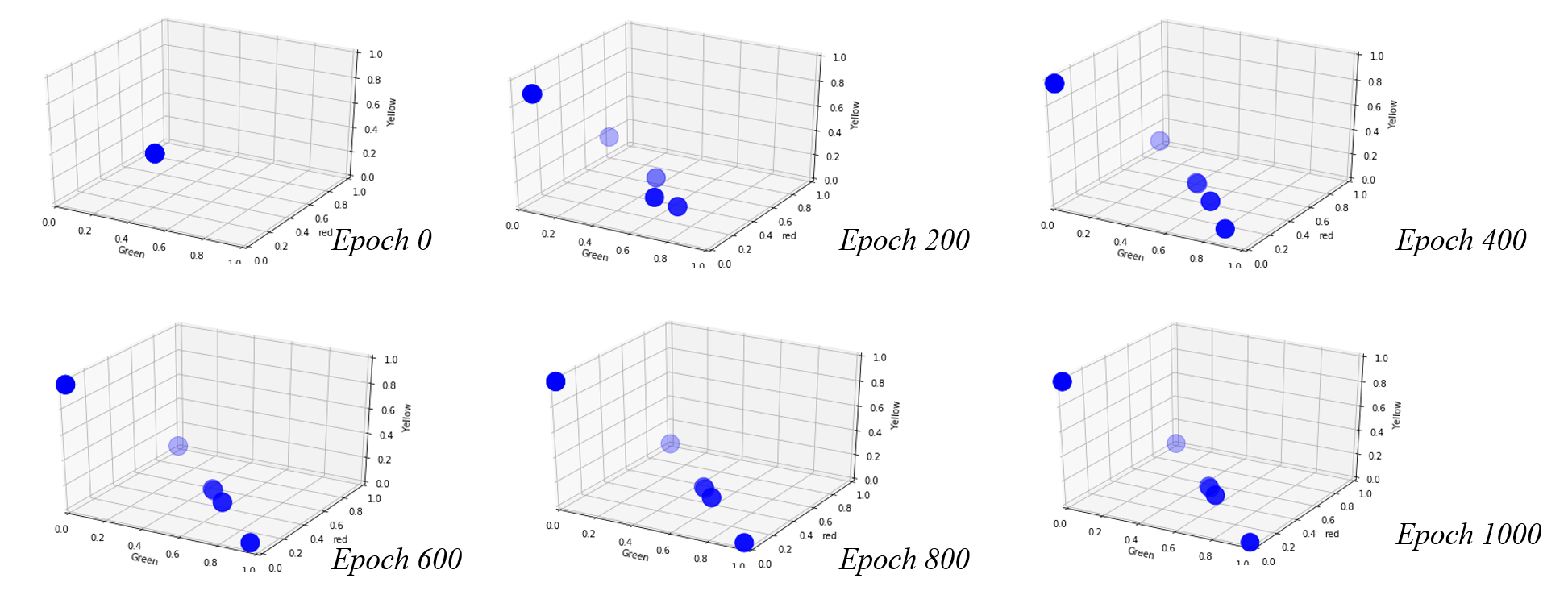
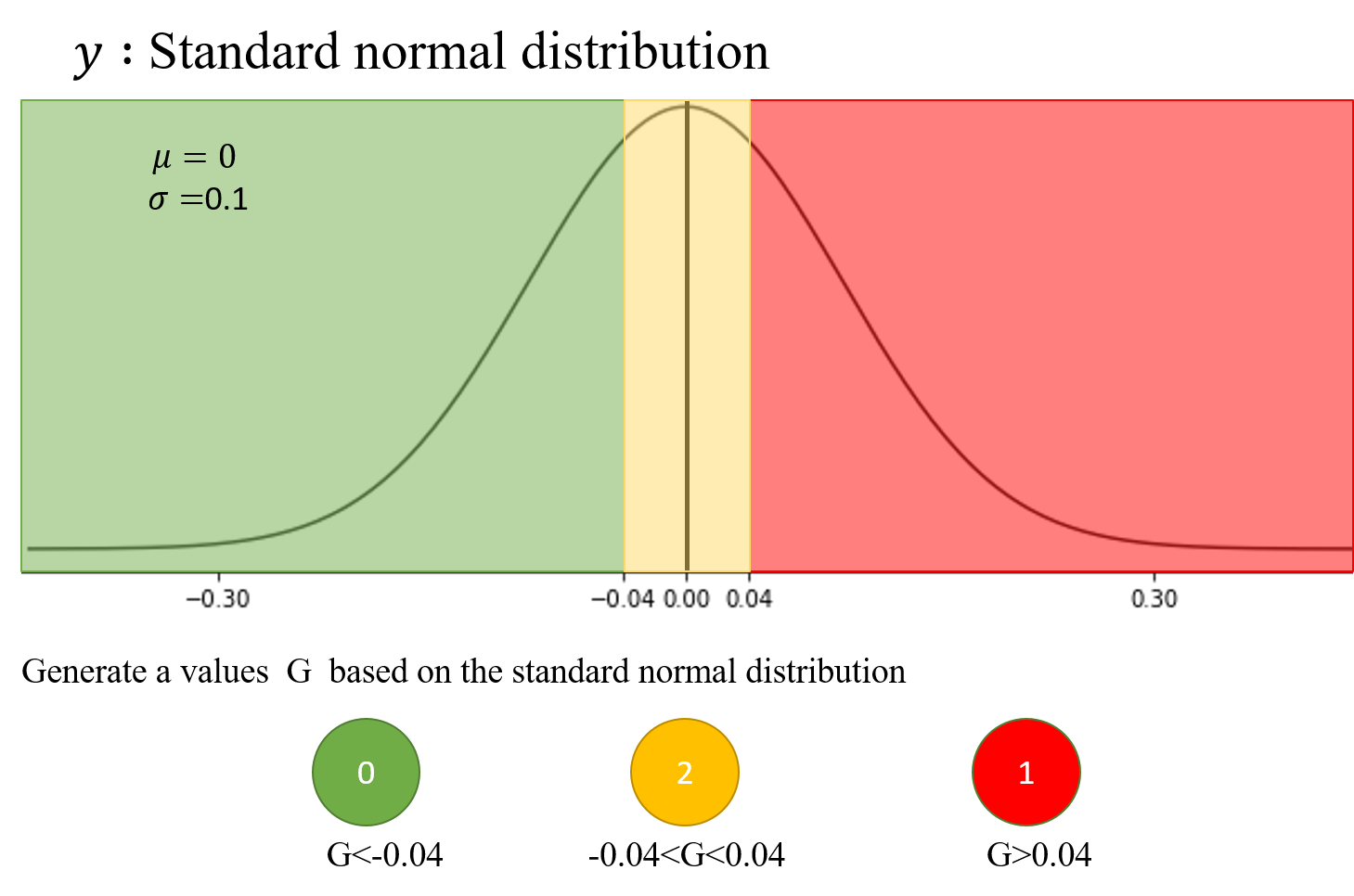
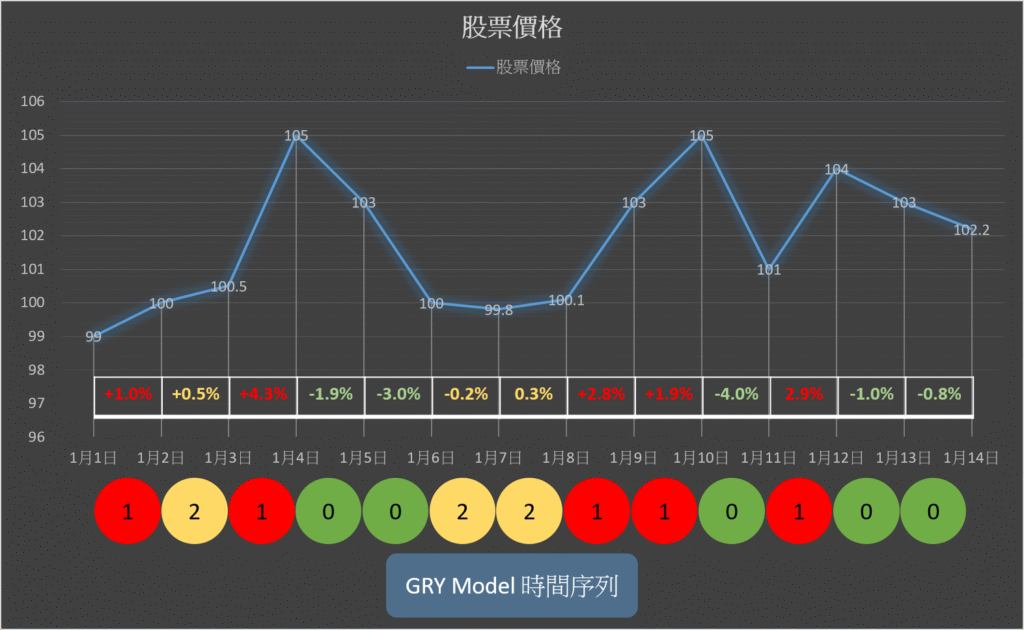
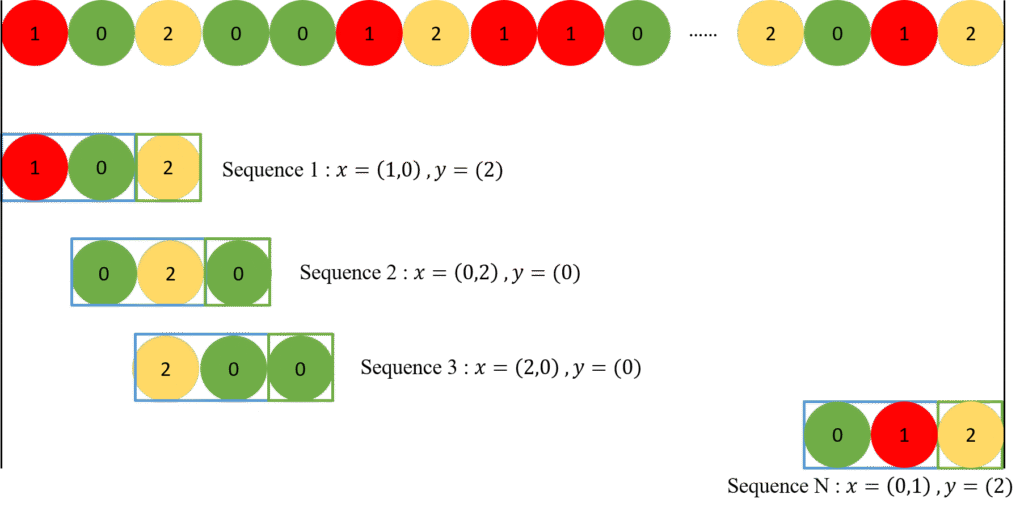
隨機漫步 98% 隨機度,GRY長序列模型
以經典理論隨機漫步設計
98%隨機程度,長時間序列10對1
探討真實隨機漫步下,神經網路的成效
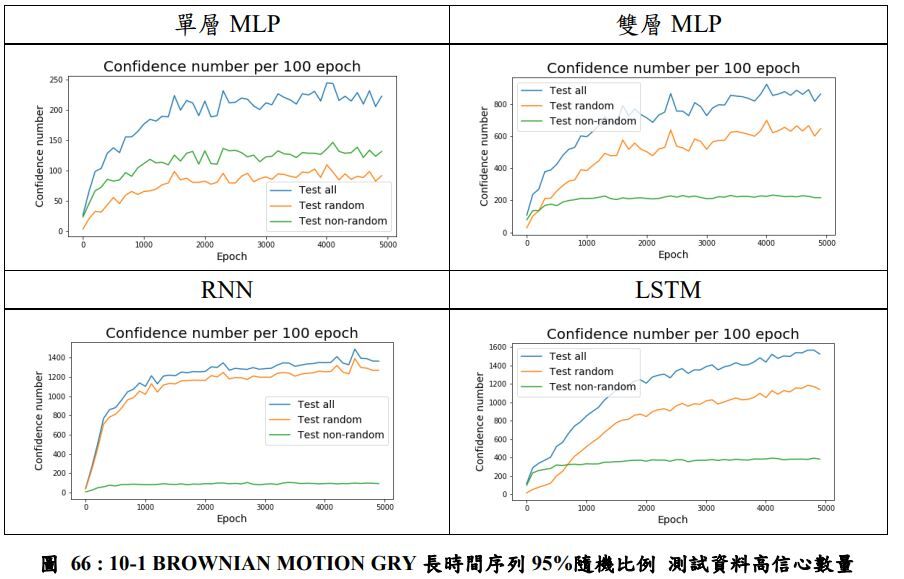
MLP、RNN、LSTM神經網路比較
經典神經網路模型除了最基礎的MLP外
還有以時間序列特色而設計且廣泛應用的RNN
以及LSTM,測試多種神經網路在高隨機下的成效

0050、2330 股票測試分析
以真實股價回測
標的為0050 與 2330 股票
測試理論世界中與真實環境中的測試差異